[论文阅读]Facebook Gorilla TSDB
最近看了一篇介绍 Facebook Gorilla 时序数据库的论文:Gorilla: A Fast, Scalable, In-Memory Time Series Database,做一些笔记摘要。
这个数据库的开源实现是Beringei,不过这个代码库现在已经不维护了。
文中压缩算法的go语言实现:go-tsz,大约1400余行代码,可以看看。
论文解读:
- http://www.nosqlnotes.com/technotes/tsdb/facebook-gorilla-1/:质量不错
- gorilla the morning paper:重点讲了其中用到的压缩算法,附有讲解算法的手绘图。
- Four Minute Paper: Facebook’s time series database, Gorilla:比较简略,观其大概
以下是笔记部分:
Facebook 此前是用一个基于HBase的时序数据库,然而随着数据量的增长,查询速度变慢(查询耗时的90分位数达到了几秒),无法满足需求。因此要自研TSDB。
Gorilla 所做的取舍是,读写速度要优先于老数据的可用性,因为多数情况下查询的都是新数据——统计表明, Facebook公司内85%的查询读取的是过去26小时的数据。过去26小时的所有时序数据都在Gorilla集群的内存中。
需求描述
• 2 billion unique time series identified by a string key. • 700 million data points (time stamp and value) added per minute. • Store data for 26 hours. • More than 40,000 queries per second at peak. • Reads succeed in under one millisecond. • Support time series with 15 second granularity (4 points per minute per time series). • Two in-memory, not co-located replicas (for disaster recovery capacity). • Always serve reads even when a single server crashes. • Ability to quickly scan over all in memory data. • Support at least 2x growth per year
总的来说,就是时序数据量巨大,查询QPS高,要求查询耗时短,高可用,容错性强。
架构
Gorilla是一个 in-memory TSDB。时序数据最终会写入HBase做持久化,而Gorilla的角色是 write-through cache。
数据格式是一个三元组:
- 字符串key:用于唯一地表征一个时序,同时作为数据分片的依据
- 64位整型的时间戳
- 双精度浮点型的值
Gorilla 是无共享架构,可以很方便地水平扩展。
时序压缩
Gorilla对每个时序内部的数据点做压缩;而没有跨时序的压缩操作。
时间戳的压缩
时间戳序列的一个重要性质是基本等间距。因此适合使用delta-of-delta算法压缩。
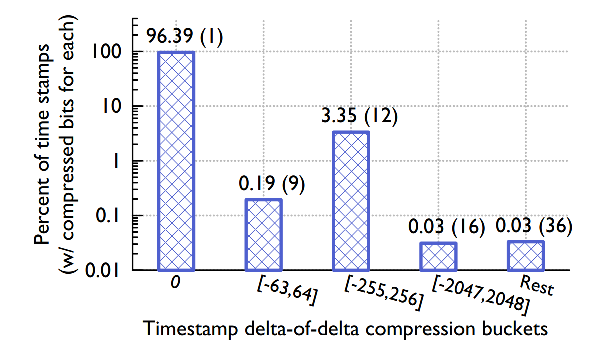
每个数据块(data block)存储了2小时的数据。block header中记录了起始时间戳。block中的第一个时间戳(即紧接着起始时间戳的后一个)使用和起始时间戳的差值(delta)来存储,这只需要占用 14 bits。后续的时间戳就用 delta of deltas 来存储。
统计数据表明:96%的时间戳都可以只用1个bit来存储,即对应着 delta of deltas 是0的情况,如下图所示。
值的压缩
值序列的两个特点:1. 相邻的值变化很小;2. 部分值是整型。 根据这两个性质,参考一些科学计算中的经验,使用XOR算法做压缩。
第一个值按原值存储,不做压缩。后续的值,使用和前一个值做XOR运算后,再加上一些编码步骤的结果存储。
统计数据表明,51%的值能被压缩到1bit,这种情况下相邻的两个值完全相同,如下图。

data block的时间跨度也是有讲究的。一般地,时间跨度越长,压缩比率就越高,当然压缩率也是有上限的。研究表明,以2小时的时间跨度为最佳,压缩率高——8字节的时间戳和8字节的值,总共16字节,压缩到了1.37字节(平均值),压缩率接近12倍。

内存数据结构
在Gorilla的实现中,最重要的数据结构是 TSmap,即 Timeseries Map。它由一个时序的共享指针的向量和一个从时序名称到时序指针的map组成。向量用来高效的扫描所有数据,map则使得查询某个时序的时间复杂度为常数级别。
磁盘存储结构
持久化方面,Gorilla 使用 GlusterFS(一个分布式文件系统),并配置为3副本。也可以使用HDFS或者其他分布式文件系统。
每个Gorilla host上有多个数据分片,每个分片有一个目录,每个目录包含四类文件:
- key list:从时序string key到整型ID的map,这个整型ID是内存中向量的索引。
- append-only logs:存储了时间戳和值,每个分片只有一个append-only log文件,所以这个log会包含多条时序。注意这不是WAL。
- complete block files:每两小时Gorilla将log转成block文件存储在磁盘上
- checkpoint files:每当生成一个完整的block文件时,Gorilla会创建一个checkpoint文件并删除对应的log文件
故障处理
为提高容错性,数据会双写到不同区域数据中心的机器上。当其中一个区域的机器挂掉后,请求会被定向到另一个健康区域的机器上。
在每个区域内,有一个基于Paxos算法的系统负责将分片分配给机器节点。当某个节点挂掉时,该系统会把它的分片重分配给其他节点,这个分片移动的过程中,写客户端会将流入的数据缓存一分钟。
其他
Gorilla 低查询延迟的特性使得开发新的分析工具成为可能。基于 Gorilla 做了相关性分析引擎。这个引擎计算时序间的PPMCC系数,来找到形状相似的时序数据之间的相关性,这些信息可用来做根因分析。
经验总结:
- 最近的数据优先于历史数据;
- 读的延迟很重要;
- 高可用性胜过资源利用率。也就是说,为了确保高可用,可以牺牲一些资源。
Comments