[笔记]PromCon 2016: The Prometheus Time Series Database
观看学习了Björn Rabenstein在PromCon 2016上的演讲The Prometheus Time Series Database。
附上相应的幻灯片。
下面摘录了一些笔记备忘。
注意:演讲时间是2016.09,而Prometheus是在2016.07发布1.0.0版本的。也就是说当时Prometheus还处于相对早期阶段,有些信息放在现在看已经过时了。但是这个视频依然具有学习的价值。
开门见山:本演讲只涉及样本的存储,而不涉及索引。
何谓样本?就是64位的时间戳+64位的浮点数值。
TSDB显著的特点就是读写模式的正交性(Orthogonal),即垂直写,水平读。这个正交性不会带来大问题,如果数据都在内存中,并且组织得合理的话。比如Facebook Gorilla就是一个内存中的TSDB。但是如果要存更多数据并且保证持久性,就要把数据放在外部存储设备中,可以是本地磁盘或者某种分布式存储。
初始的想法是使用BigTable类的KV存储, 将指标名+标签+时间戳作为key,将指标的值作为value。如下图所示:

确实有一些TSDB将BigTable类的数据库作为后端,例如OpenTSDB使用HBase,KairosDB使用Cassandra。
这初看上去比较浪费存储空间,不过由于这些数据库本身有内置的数据压缩功能,所以还好。
考虑到我们的设计目标不包含集群化,所以我们想要的是一个本地存储,这样就排除了BigTable、HBase、Cassandra等。
Prometheus使用LevelDB,但是仅仅用在索引的存储上。在更早的原型阶段,Prometheus曾经将LevelDB用作样本的存储,并且做了许多调整。但这些调整并不尽如人意,所以才决定实现自己的样本存储层。
BigTable类存储的主要问题在于,样本在内存和在k/v存储中的表现形式不一样。转换需要开销,而且在存储层的优化对内存中的样本表现并无帮助。
注:没看懂这里的问题具体指什么 … 不过Prometheus 存储层的演进文中提到:“时序数据比通用键值数据有更显著的特征。即使键值数据库能够压缩数据,但针对时序数据的特征,使用特殊的压缩算法能够取得更好的压缩率。” 我觉得是有道理的。
Prometheus和Facebook Gorilla作比较 两者是并行开发的,开发时并不知道对方的存在,但最终却有一些共通之处。
-
Gorilla数据都在内存中,而Prometheus需要写数据到本地磁盘
-
时间精度:Gorilla 是秒,Prometheus是浩渺
-
Gorilla的blocks是固定时长(2h),Prometheus的chunks是固定大小(1kiB)
-
解码:Gorilla 不关心解码,因为解码是由客户端完成的;Prometheus则需要在服务端实现解码
-
压缩率:Gorilla - 1.37bytes/sample; Prometheus - 3.3bytes/sample
Gorilla和Prometheus的V1编码都是基于double-delta的。然后作者在阅读了Gorilla的论文后,受其启发对Prometheus V1编码做了一些改良,这就是V2编码版本。
使用一个命令行flag -storage.local.chunk-encoding-version
来区分v1和v2。
每个chunk的编码版本可以不同。在解码时,会根据chunk中的版本字段是V1还是V2来决定解码的方式。编码版本对客户端是透明的。
时间戳压缩
(1)比较Prometheus V1和Gorilla:Prometheus V1是先做delta,然后用数据的前两个点拟合出一条直线,计算每个点和这条直线的偏差值,这就是它的double delta。而且Prometheus为了做到随机读取,每个样本的位宽度是固定的。
Gorilla则是类似于二阶导数的double delta,但它使用了效率更高的每个样本的位宽度可变的编码方式(有点像varint);它不用关心解码,所以能够这样做。
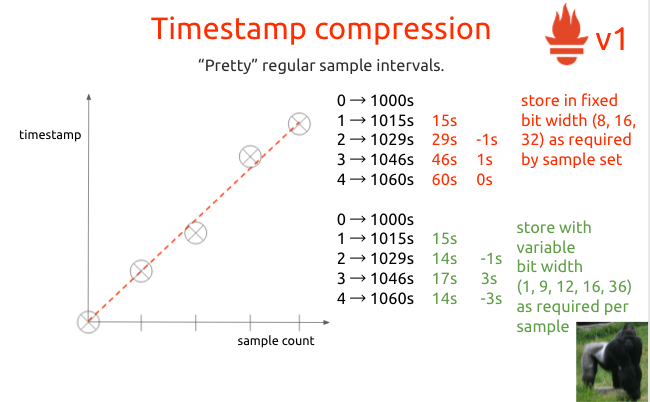
(2)比较Prometheus V2和Gorilla:几乎类似,只是bit bucket不同,以及对于double delta为0的情况的处理手段不同。

值的压缩
值是64位的浮点数。大部分情况下值的变化小,如果直接存原始数据就太浪费了。
(1)对常数值的时序的处理:Prometheus V1/V2都是只存储值一次,后面的值就不存了,0bit/sample;Gorilla是存第一个值,后面的值是存当前值和前一个值的XOR计算结果,也就是0,即1bit/sample。
最好(最省存储空间)的情况是值保持为常量,有着绝对规律的抓取间隔,算下来平均0.066bit/sample。
(2)对规律增长的值的处理:比如Counter。Prometheus V1采用和时间戳同样的double-delta编码,尽可能使用整型(8,16,32位),不行就用float32,如果必须用64位,那么直接存原始的float64数据。这样做,对于斜率总是一样的值,只需要0bit。
而Gorilla还是存第一个值,后面的值则存储当前值和前一个值的XOR结果,然后参考前一个XOR值做编码(类似于double-delta,比较复杂)。
(3)对于随机的值:Prometheus V1首先会尝试double-delta编码,也很可能会降级为直接存储float64值。Gorilla的编码方式不变,随机的数据可能导致更多的开销(即每个样本超过64bit)。
Prometheus V2的值编码会从下面这个列表中依次挑选出第一个工作的编码格式:
- zero encoding
- integer double-delta encoding
- XOR float encoding (基于Gorilla做了一些改良)
- direct encoding(当XOR结果是64bit甚至更多时)
在SoundCloud的测试集上这样编码的结果是1.28bytes/sample。
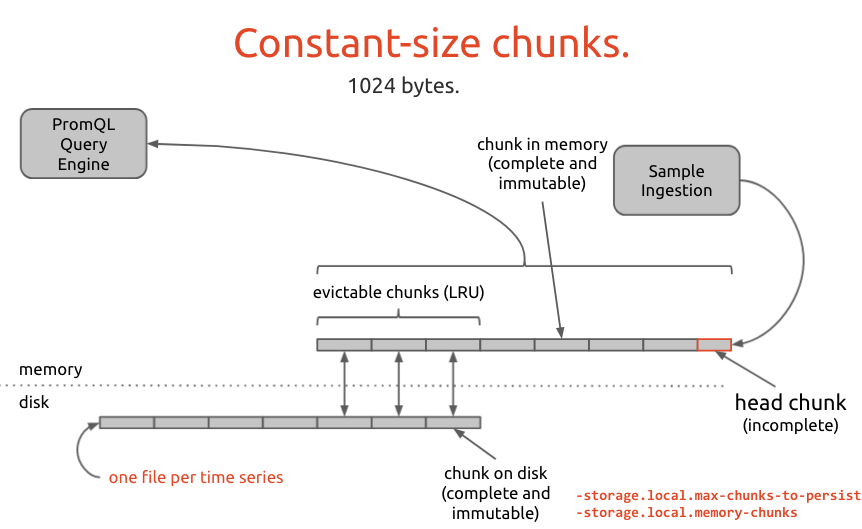
样本数据是用固定大小的chunks来组织的。chunk的大小是常量,即1024bytes。
在内存中的chunk分为两种:完整且不可变的;不完整的head chunk。样本写入的就是head chunk。
磁盘上的chunk是完整且不可变的。磁盘上每个时序一个文件。
内存中的chunk会定期地写入到磁盘上(有flag来配置内存中chunk数量和做持久化的chunk的最大数量)。
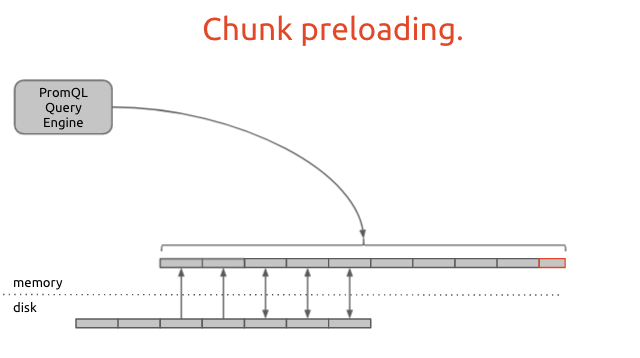
查询完全依赖于内存中的chunk。当需要不在内存中的chunk数据时,查询引擎会将磁盘上的chunk预加载到内存中。
Comments