ZooKeeper初探
ZooKeeper Overview 内容
ZooKeeper 是一个用于分布式应用的分布式协调服务。它提供了一系列简单的“原语”(primitive),分布式应用可以基于这些原语实现更高层级的同步、配置管理、分组和命名服务。
ZooKeeper的设计目标包括:
- 简单(simple):数据模型、API、使用方式简单
- 重复(replicated):在多个(通常是奇数个)节点上重复,保证了其高可用。这些节点的集合叫做 ensemble
- 有序(ordered):所有的更新操作都是有序的
- 快速(fast):尤其是在读多写少的场景下
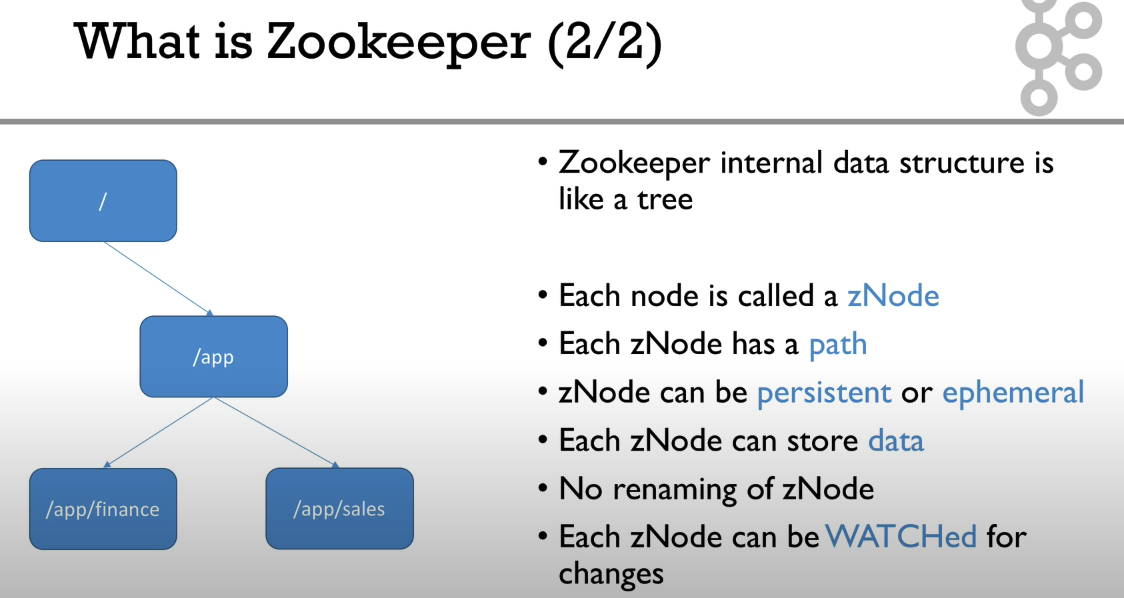
ZooKeeper的数据模型是一个类似于标准文件系统的分层级的树形结构,树中的每个节点叫做znode。znode的名称或者ID是由正斜杠/连接的路径序列,例如/,/app1,/app1/p1 等。每个znode都有相应的数据(data),同时也可以有子节点。znode的数据量一般不大,是byte到kilobyte的量级。数据有相应的版本号,每次更新操作会加一。对数据的读写操作都是原子的。
有两种znode,分别是persistent和ephemeral。后者会在创建该znode的session终止时被删除。
客户端可以watch znode,当该znode发生变化时,客户端会接收到通知。
ZooKeeper提供了一系列的保证:
- 顺序一致性(Sequential Consistency):从客户端发出的更新操作会以相同的顺序被应用
- 原子性(Atomicity):更新要么成功,要么失败,不存在中间状态
- 单一系统镜像(Single System Image):客户端不管是连接到ensemble中的哪个服务器,它看到的服务状态都是一样的
- 可靠性(Reliability):更新操作会被持久化,直到被覆盖写
- 及时性(Timeliness):客户端看到的系统状态是最新的(在一定时间范围内)
ZooKeeper提供了非常简约的API。
- create:创建znode
- delete:删除znode
- exists:判断某个znode是否存在
- get data:读取znode的数据
- set data:将数据写入znode
- get children:获取znode的子节点
- sync:waits for data to be propagated
参考
其他一些视频和幻灯片的摘录
(1)What is Zookeeper?

(2)ZooKeeper explained
Zookeeper存储了一些集群内部必须保持同步和一致的信息,包括:
- 哪个节点是master节点?
- 哪些任务被分配给了哪个worker?
- 哪些worker当前是可用的?

常见的故障模式有:
- master节点挂了,需要使用一个备用节点作为master
- worker节点挂了,它的工作需要被重新分配给其他节点
- 网络故障,集群中部分看不到另一部分

在分布式系统中有一些“原语”(Primitive)操作:
- 选主
- 故障感知
- 组管理
- 元数据管理

但是ZooKeeper的API没有直接暴露这些原语操作,而是更为通用,使得应用能够更简单地使用它们。

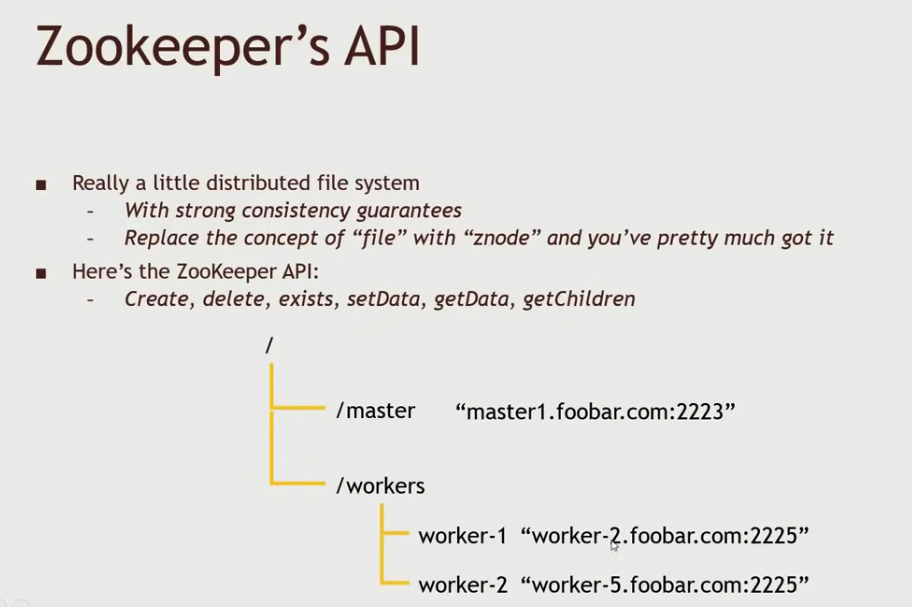
ZooKeeper 实际上是一个小型的分布式文件系统,保证了强一致性。不过使用了znode来代替file的概念。
ZooKeeper的API包括了:create,delete,exists,setData,getData,getChildren。
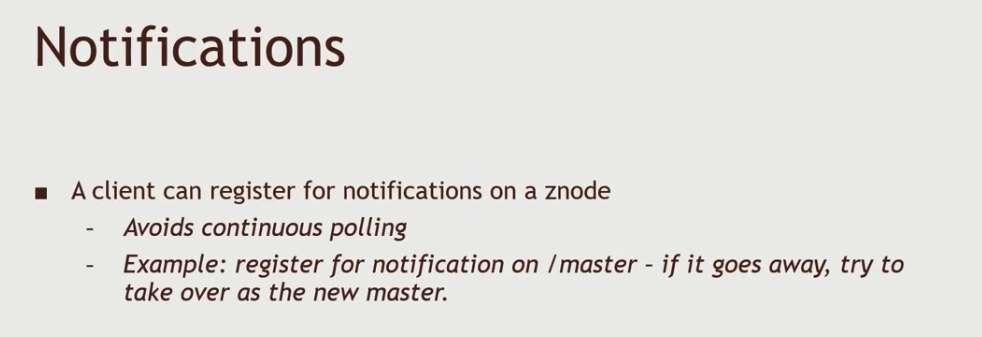
ZooKeeper的客户端可以针对某个znode注册,这样在该znode发生变化时能够收到通知,这样避免了持续性的轮询。
znode分为persistent和ephemeral两种:
- persistent znodes会一直保存着,除非被显式地删除
- ephemeral znodes会在创建它的客户端挂掉或者和ZooKeeper失去连接时被删除

ZooKeeper的整体架构如下:
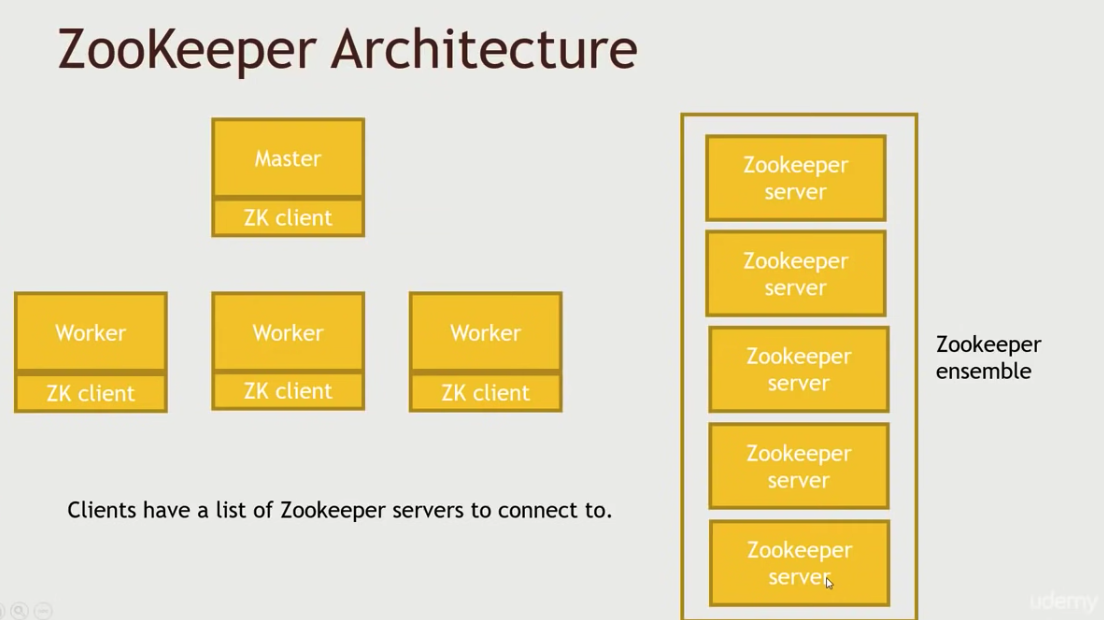
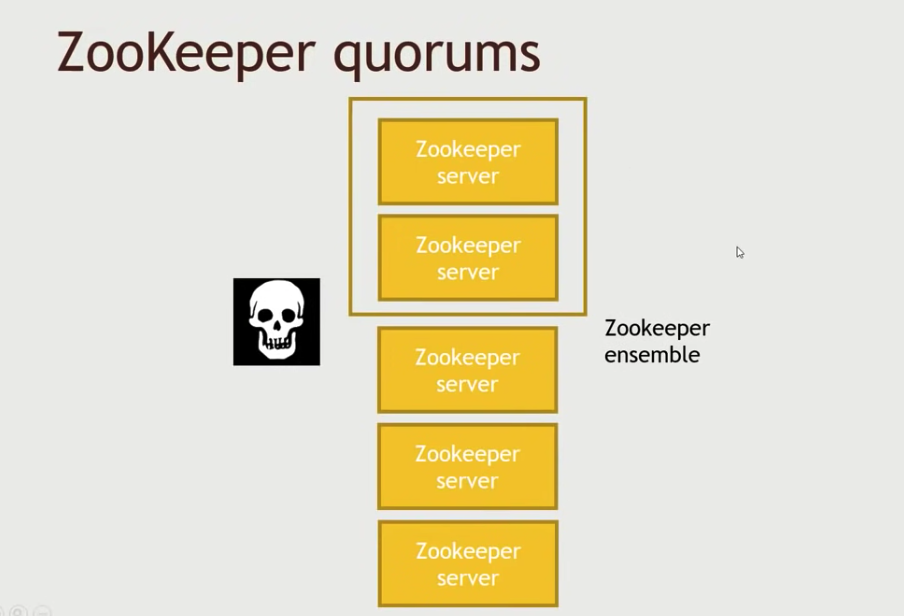
ZooKeeper quorums:
如果quorum level是3,那么至少需要5个ZooKeeper server。
(3)What is Zookeeper and how is it working with Apache Kafka?

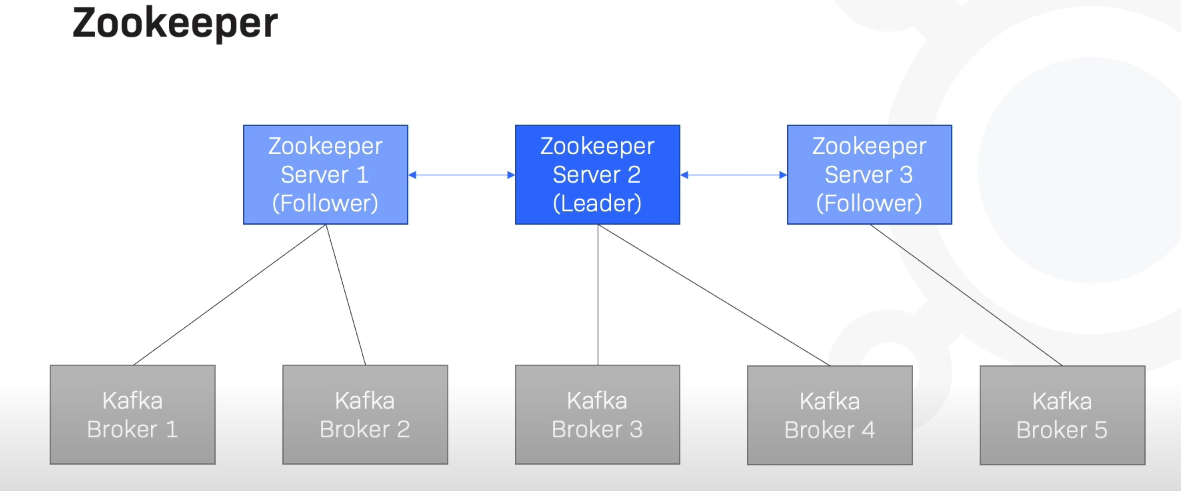
可以看出Kafka在逐渐“去ZooKeeper化”,过渡到自身实现的Raft协议。
Comments